After Opting Out: How Google Still Uses Web Content For AI Training

Table of Contents
The Illusion of Opting Out
Understanding Google's Data Collection Policies
Navigating Google's privacy policies can be a labyrinthine experience. While Google offers various opt-out options, understanding their full implications is crucial. The reality is that Google's data collection practices are multifaceted, extending beyond individual user settings.
- Web Crawlers: Google's web crawlers constantly scan the internet, indexing billions of web pages. This process, while essential for search functionality, also captures vast amounts of data used for AI training. Opting out of personalized ads doesn't necessarily prevent this type of data collection.
- User Activity: Even with privacy settings adjusted, Google collects data from your interactions with its services. This data, anonymized or not, contributes to the broader datasets used in AI model training.
- Third-Party Data: Google often integrates data from various third-party sources. This further complicates the picture, making a complete opt-out nearly impossible.
The Public Nature of Web Content
A key argument supporting Google's use of web content for AI training centers on the public accessibility of this information. The premise is that publicly available content, including text, images, and code, is considered fair game for AI model development, regardless of individual user preferences or opt-out choices. This argument often cites legal precedents and industry standards related to data scraping and the use of publicly available information. However, this perspective often overlooks the ethical considerations of aggregating and using this data without explicit consent.
How Google Uses Web Data for AI Training
The Role of Web Scraping
Web scraping is a crucial component of Google's data scraping efforts. This automated process extracts data from websites, forming the raw material for its extensive datasets. The scale of this operation is immense, allowing Google to train powerful AI models on a massive scale.
- Text Data: Vast amounts of text data from websites, books, articles, and code repositories contribute significantly to the training of language models like LaMDA.
- Image Data: Image data from across the web helps train computer vision models, improving object recognition and image analysis capabilities.
- Code Data: Code repositories like GitHub are invaluable sources of data for training AI models that can understand, generate, and debug code. This data is crucial for the improvement of AI tools that assist programmers.
Specific Google AI Projects and Data Sources
Several high-profile Google AI projects rely heavily on web data for their development.
- LaMDA (Language Model for Dialogue Applications): LaMDA's conversational abilities are honed through training on massive text datasets scraped from the internet, including public conversations, books, and code.
- PaLM (Pathways Language Model): Similar to LaMDA, PaLM utilizes enormous datasets derived from publicly available web content, resulting in a powerful language model capable of complex reasoning and problem-solving.
Ethical and Privacy Implications
Concerns about Unintended Bias
A significant concern surrounding Google AI training is the potential for bias in the resulting AI models. Since these models are trained on web data reflecting existing societal biases, the models can perpetuate and even amplify these biases.
- Gender Bias: AI models might exhibit gender stereotypes if trained on datasets containing predominantly male or female voices in specific contexts.
- Racial Bias: Similar biases can appear regarding race, ethnicity, and other demographic factors, potentially leading to unfair or discriminatory outcomes.
The Ongoing Debate about Data Ownership and Consent
The ethical use of publicly available data for AI training is a complex and evolving area. The debate centers on the balance between leveraging public information for technological advancement and respecting individual data rights and consent. While the data may be publicly accessible, the question of whether its aggregation and use for AI training constitutes a form of implicit consent remains contentious.
Conclusion
The limitations of opting out of Google's data collection highlight the challenges of controlling one's digital footprint in the age of AI. Google's extensive use of web content, even after opt-outs, for Google AI training raises crucial ethical and privacy questions. The potential for bias in AI models trained on biased data underscores the need for responsible data handling practices. Understanding the complexities of Google AI training and its implications for user data is more crucial than ever. We urge readers to delve deeper into Google's privacy policies, explore frameworks for ethical AI development, and participate in the ongoing public discourse surrounding data ownership and consent in AI. What are your thoughts on the ethical implications of using publicly available data for AI training?
Featured Posts
-
 Enhanced Payment Options On Spotifys I Phone App
May 04, 2025
Enhanced Payment Options On Spotifys I Phone App
May 04, 2025 -
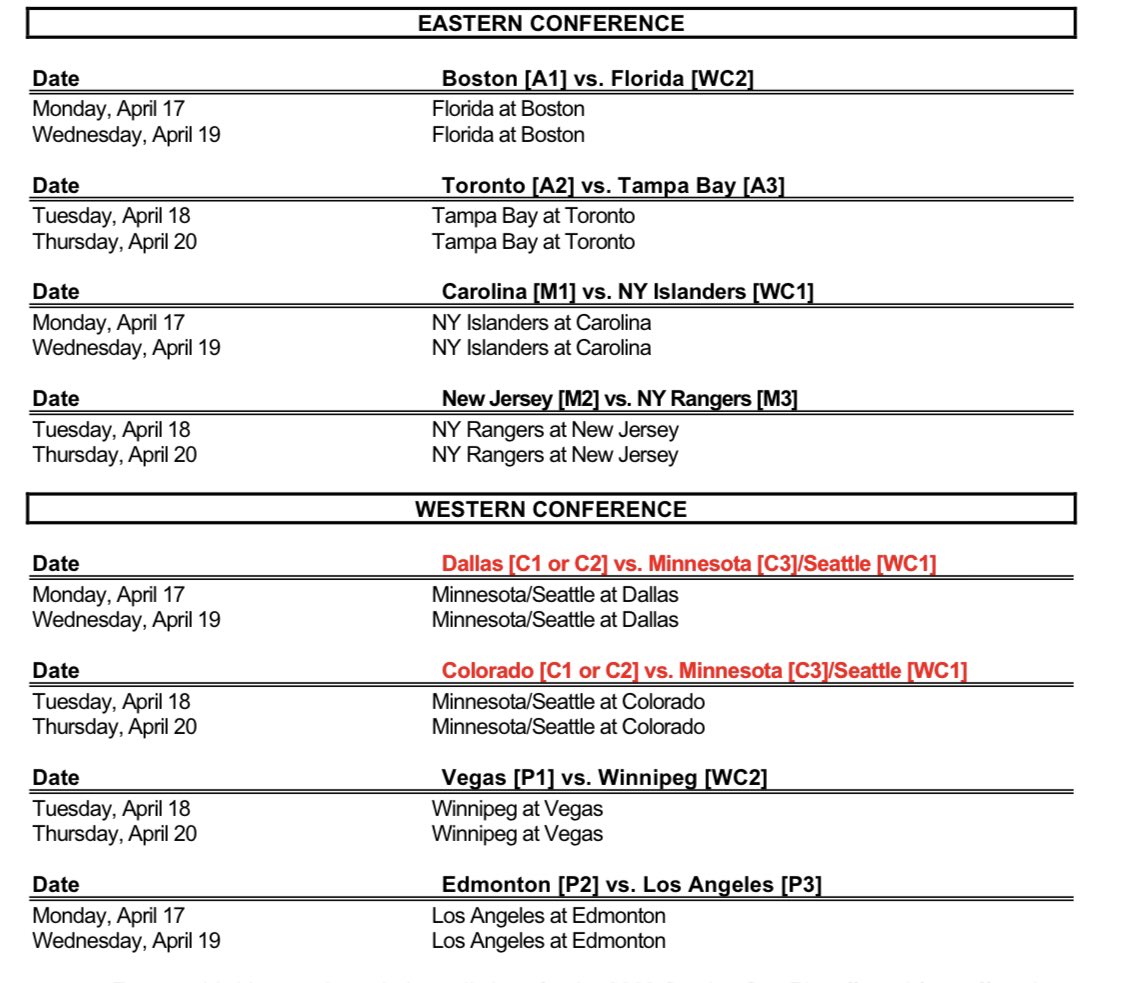 Nhl Playoffs First Round A Comprehensive Guide
May 04, 2025
Nhl Playoffs First Round A Comprehensive Guide
May 04, 2025 -
 Mark Carneys White House Visit Discussions With Trump Next Week
May 04, 2025
Mark Carneys White House Visit Discussions With Trump Next Week
May 04, 2025 -
 Marvels Thunderbolts A Necessary Gamble For The Mcu
May 04, 2025
Marvels Thunderbolts A Necessary Gamble For The Mcu
May 04, 2025 -
 Nhl Playoff Standings A Deep Dive Into The Western Wild Card Race
May 04, 2025
Nhl Playoff Standings A Deep Dive Into The Western Wild Card Race
May 04, 2025
Latest Posts
-
 Nhl Roundup Panthers Rally Avalanche Routed By Johnston And Rantanen
May 04, 2025
Nhl Roundup Panthers Rally Avalanche Routed By Johnston And Rantanen
May 04, 2025 -
 Analyzing The Nhl Playoff Standings Ahead Of Showdown Saturday
May 04, 2025
Analyzing The Nhl Playoff Standings Ahead Of Showdown Saturday
May 04, 2025 -
 Nhl Playoff Standings Crucial Games On Showdown Saturday
May 04, 2025
Nhl Playoff Standings Crucial Games On Showdown Saturday
May 04, 2025 -
 Showdown Saturday Your Guide To The Nhl Playoff Standings
May 04, 2025
Showdown Saturday Your Guide To The Nhl Playoff Standings
May 04, 2025 -
 Nhl Playoffs Showdown Saturday Standings And Key Matchups
May 04, 2025
Nhl Playoffs Showdown Saturday Standings And Key Matchups
May 04, 2025

